첫 리뷰 논문은 transformer-xl 입니다.
ACL에 2019 발표되었고, 그 이전부터 arxiv에 공개되어 1000이 넘는 인용횟수를 자랑하는 논문이다.
저자들은
Zihang Dai, Zhilin Yang, Yiming Yang , Jaime Carbonell , Quoc V. Le , Ruslan Salakhutdinov
Carnegie Mellon University, Google Brain
그럼 논문을 대략적으로 리뷰해보겠습니다.
PS. LM쪽 researcher가아니라 자세한 실험내용에 대해서는 많이 생략하였습니다.
Abstract
transformer(attention is all you need) 논문이 나오면서 long-term dependency를 처리하는 모델로서 뛰어난 성능을 보여왔다.
그러나 보통 fixed-length context에 대해 제한이 있는 단점이 있다. (길이를 고정해서 사용함. 너무 길면 computation, memory 이슈가 있음)
이러한 문제를 해결하기 위해 저자는 Transformer-XL이라는 아키텍쳐를 제안
segement-level에서의 recurrence mechanism으로 longer-tem dependency를 학습할 수 있다.
그 결과 transformer, 기존 RNN계열보다 더 긴 sequential 정보를 처리할수 있다.
Introduction
LM(language modeling)에서 long-term dependency를 학습하는 것은 성능에 많은 영향을 미침.
기존에 LSTM-based / Transformer-based 들이 LM에서 좋은 성능을 보였다. (특히 transformer계열)
그러나 transfomer의 경우 segement 단위로 processing 함.
sequence가 매우 길때, 전체 context 정보 고려하지 못함 -> LM성능에 악영향
또한, segment가 fixed-length로 짤리다보니, segment 처음 부분 예측할때 character 예측하는 정보가 없어 "context fragmentation" 문제가 생기기도함
이런 문제를 해결하기 위해 Transformer-XL을 제안
- 매 segment에서 hidden state를 연산할때, segment 내에서만 연산이 아니라 이전 segment의 hidden state를 받아서 사용한다.
- 이러한 방법으로 segment-level reccurence mechanism을 만든다.
- 이 방식을 위해 relative positional encoding이 필요, 사용함
Model
1. Vanilla transformer language models
Train:
LM에서 self-attention을 사용하려면, 중요한 문제가
"how to train a Transformer to effectively encode an arbitrarily long context into a fixed size representation"
이라고 한다.
가장 간단한 방법은 전체 sequence를 모두 transformer에 넣어주면 되지만, memory와 computation문제로 현실에서는 이처럼 해결하는 것이 매우 어렵다.
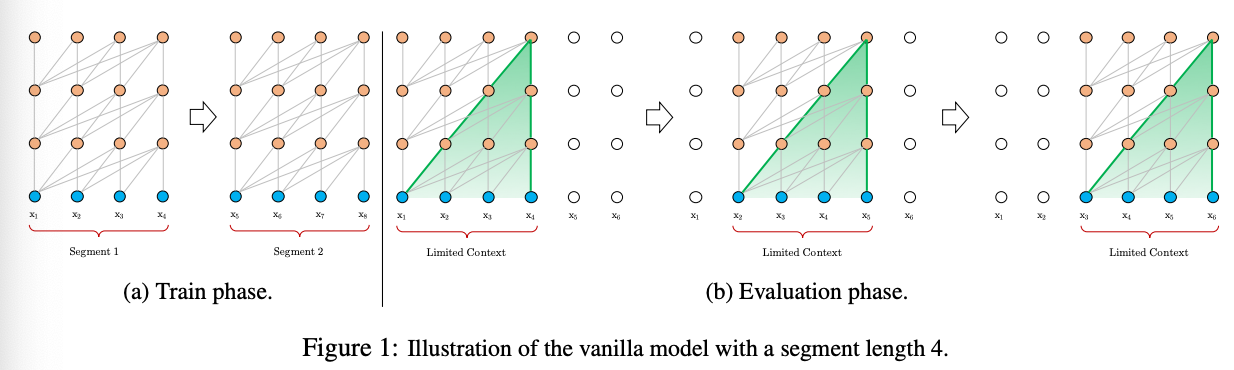
다른 방법은 (적용가능하지만 crude approximation한) 전체 corpus를 짧은 segment로 잘라서 각각 processing하는 것인다.[Figure 1]
limitations 1. possible dependency length가 segment length로 bounded된다.
limitatnios 2. sequence를 fixed-length segment로 단순 chunking하면, intro에서 언급한 context fragmentation 문제가 발생한다.
Eval:
segment를 받아 마지막 token prediction함.
이렇게 한 position씩 shift하면서 연산 from scratch.[Figure 1(b)]
이런 방식으로 inference하면, 긴 문장도 처리할 수 있으나, 연산/속도 측면에서 매우 cost가 높음.
2. Segment-level recurrence with state reuse
위의 언급된 문제점들을 해결하기위해 recurrence mechanism을 tranformer에 도입.
학습과정에서 이전 segment의 hidden state sequence들을 재사용하기 위해 fixed and cached 함.
이전 segment의 hidden state를 사용함으로써 long-term dependency 고려가능, context fragmentation 문제 해결.
수식
길이 L의 연속된 segments
$s_{\tau} = [x_{\tau,1}$$, ..., x_{\tau,L}]$
$s_{\tau+1}=[$$x_{\tau+1,1}$$, ...,$$x_{\tau+1,L}]$
$h^{n}_{\tau} \in \mathbb{R}^{L \times d}$ : $\tau -th$segment의 $n -th$ layer에서 hidden state sequence
일때
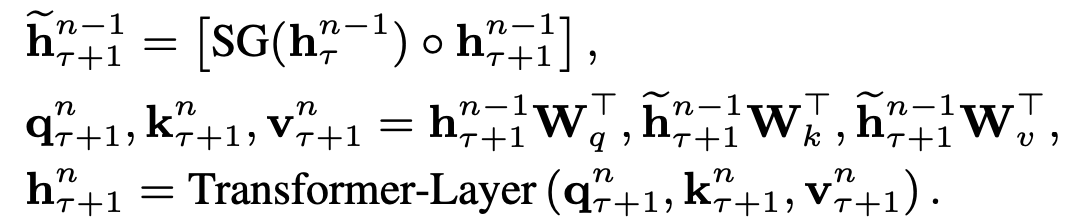
로 계산된다.
SG 는 stop gradient로 이전 segment의 state로는 gradient 전파를 막는 역할을 한다고 보면된다.
$[\circ ]$는 concatenation을 뜻한다.
이수식을 보면, [figure2(a)] 처럼 연산됨을 확인할 수 있다.
transformer의 self attetion을 수행할 때, key, value를 위 수식처럼 이전 segment의 hidden state까지 concat해서 봄으로써, long-term dependency를 본다고 이해하면 될 것 같다.

이 reccurent mechanism은 연속된 두개의 segment에 적용되어서 계속 진행되므로 segment level recurrence 라고 말한다.
이방식은 layer마다 수행되므로, given step에서 최대로 볼 수있는 길이는 segment 길이(L)과 laye의 수(N)의 곱이라고 볼 수 있다.$O(N \times L)$.
이러한 연산을 위해서는 이전 segment의 hidden state값을 알고 있어야 하기에 cache 해 놓아야한다.
또한, 이전 segment와 현재 segment를 동시에 고려하기에, absolute postional encoding이 아니라 relative positional encoding을 사용해야한다고 저자는 말하고 있다.
* relative positional encoding 내용 생략..(논문에는 설명되어있습니다.)
Experiments

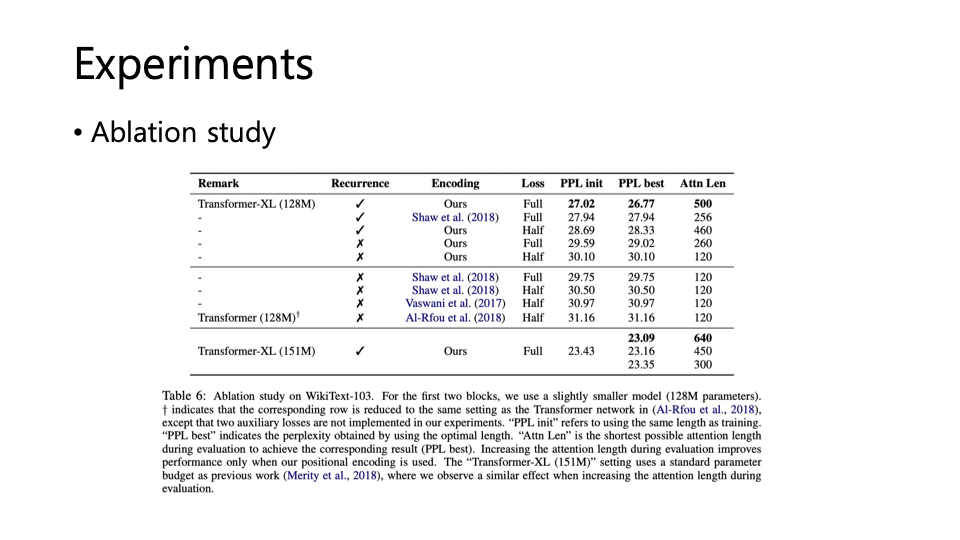
아래 파일은 혼자 논문 보면서 ppt로 간략하게 정리해본 내용입니다.(블로그와 내용 거의 유사)
참고
•https://arxiv.org/pdf/1901.02860.pdf
•http://mlgalaxy.blogspot.com/2019/07/transformer-xl.html
댓글